关于监督学习、无监督学习、半监督学习、强化学习、自监督学习的区别
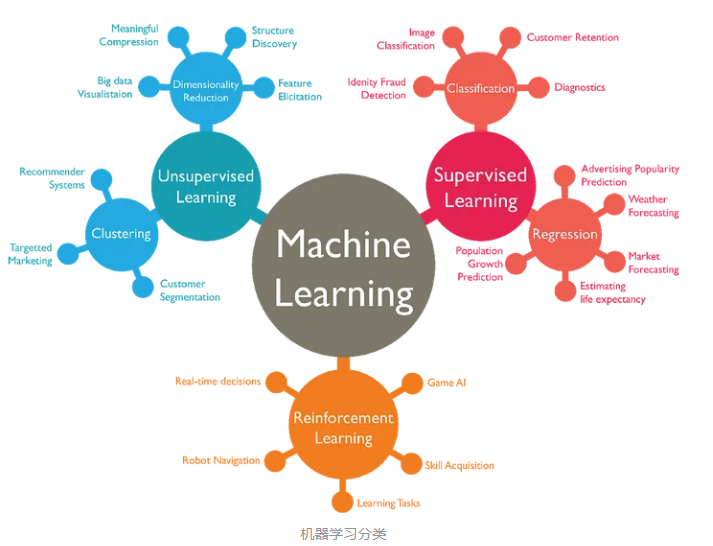
监督学习(Supervised Learning 或Supervised Machine Learning)
使用标记数据集来训练算法,一边训练后的算法可以对数据进行分类或准确预测结果。
可分成两类:分类(线性分类器、支持向量机、决策树、随机森林等)、回归(使用一种算法理解因变量和自变量之间的关系,有助于根据不同的数据点来预测数值)
无监督学习(Unsupervised Learning)
用算法来分析并聚类未标记的数据集,以便发现数据中隐藏的模式和规律,而不需要人工干预。
主要用于三个任务:聚类、关联和降维
- 聚类(Clustering):数据挖掘技术,用于根据未标记数据的相似性或差异性对他们进行分类分组。适用于细分市场的划分、图像压缩等。
- 关联(Association):使用不同的规则来查找给定数据集中变量之间的关系。常用于推荐算法。
- 降维(Dimensionality Reduction):当特定数据集中的特征(或维度)太多时,在保持数据完整性的同时,将数据输入的数量(维度)减少到可管理可操作的大小。常用于数据预处理阶段,例如用自编码器把图片数据中的噪点去除,以提高图像质量。
对比:
监督学习和无监督学习本质区别就是用来训练的数据是否进行标注。
监督学习处理数据比较耗费算力,但结果比较准确,可以解释。无监督学习处理数据算力开销不大,但是无法解释,也许是可以挖掘出未被人类注意的新规律的。
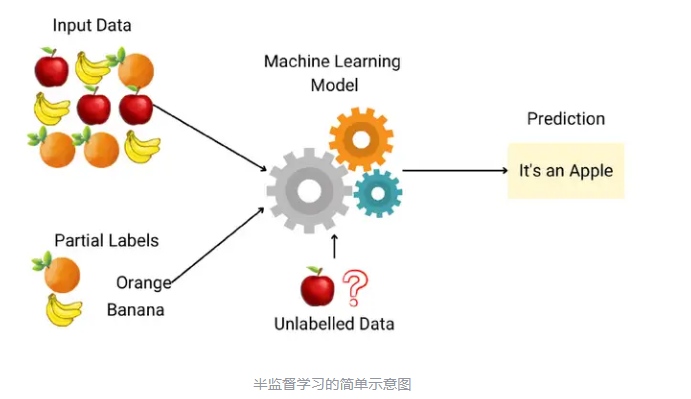
半监督学习(Semi-supervised Learning)
适用情况:相对较少的标记数据+大量未标记数据
强化学习(Reinforcement Learning)
对算法执行的正确和不正确行为分别进行奖励和惩罚的制度,目的是使算法获得最大的累积奖励,从而学会在特定环境下做出最佳决策。
- 代理人,Agent:一个我们试图学习的实体(即玩家在游戏中所使用的角色);
- 环境,Environment:代理人所处的环境(游戏所设置的游戏世界设定);
- 状态,State:代理人在环境中获得自己当前状态的各种信息;
- 行动,Actions:代理人在环境中所执行的与环境交互的各种动作(马里奥游戏中的行走、跑步、跳跃等等);
- 奖励,Reward:代理人从环境中获得的行动反馈(在马里奥的游戏里,即为正确的行动增加的积分/硬币,是一个积极的奖励。因落入陷阱或被怪物吃掉而丢失积分,或损失一条“命”,则是一个消极的奖励);
- 策略,Policy:根据代理人当前的状态决定一个合适的决策,以最大化地在未来某个时间段内获得正面报酬,最小化获得负面的惩罚;
- 价值函数, Value function:决定什么才是对代理人是有益的。
自监督学习(self-supervised learning)SSL
不需要人工标注训练数据,主要训练从大规模的无监督数据中挖掘能够应用于自身的监督信息,从而从输入的一部分数据中去学习另一部分。
自监督学习可以通过对图片的剪裁、九宫格切割后再打乱、镜像或降低色彩饱和度等操作,让机器学会改变后的图像与原图像之间存在着十分接近的联系,这种紧密联系在二维的 Embedding 坐标空间中显示为极度靠近的坐标点。不仅仅是图片,自监督学习可以对音频、视频、文本进行同样的学习。然而这些紧密的联系,是无法通过人类标注员来操作的。就好比我们可以对图中的鸟标注为“鸟”,但是自监督学习只会把它标注为 Embedding 空间中数据结构位置信息,这在本质上和人类给这幅图标注为“鸟”是一个意思。
可以看出,自监督学习很容易被误解为无监督学习中的聚类,因为他们也同样是把不同的未标记的事物进行分类,但其实自监督学习是在最大化同一类样本在 Embedding 空间中表征的相似性,同时最小化不同类样本之间表征的相似性。要做到相同类别的事物表达相近,不同类别的事物表达要更远,也就是说要极端化这种对比。通过这样的极端化过程,编码器(Encoder)能学到样本在 Embedding 空间中的许多潜在特征。所谓物以类聚,人以群分!
可以对巨量数据自动进行更广泛的标注,对下游任务产生帮助。也适合挖掘大量的数据集中不被人类关注过的“隐蔽”信息。
分布式训练
由于硬件资源的限制,使用多台机器共同完成训练任务。
(以下是突然找到了好早之前的笔记)
解耦设计
将不同部分分离开来,以提高灵活性、可维护性和性能。
这种方式减少了不同部分之间的依赖关系,使他们可以更加独立地设计、实现和维护。
Dropout
作用:有效的缓解过拟合现象
在batch中,忽略一半的特征检测器(让一半的隐层节点值为0)。这种方式减少了特征检测器(隐层节点)之间的相互作用
在前向传播的时候让某个神经元的激活值以一定的概率p停止工作,这样可以使模型的泛化性更强,因为它不会太依赖某些局部的特征
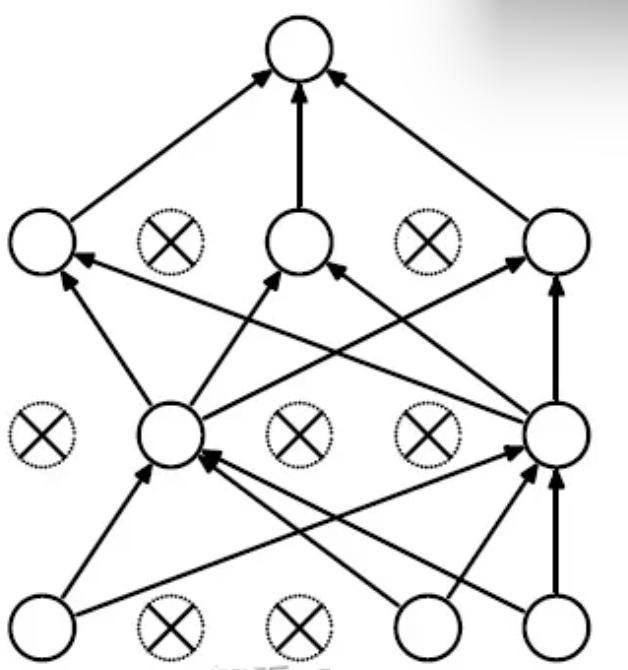
dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征