UPDP
UPDP: A Unified Progressive Depth Pruner for CNN and Vision Transformer
简要介绍:一种很厉害的剪枝方法,适用于cnn和transformer
传统剪枝(pruning)
模型剪枝算是模型压缩的一种,直接减少参数量,为了减少对硬件的要求、加速模型推理和落地。(模型稀疏化)
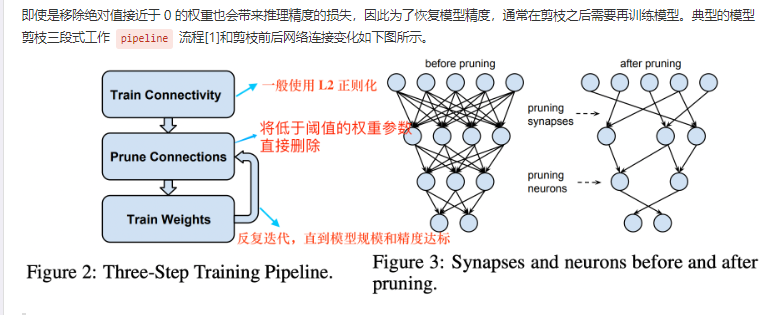
做法:直接删除部分不重要的权重参数,减少参数量和计算量,尽量使精度不受影响。
在神经网络中,非结构化稀疏包括权重稀疏、激活稀疏、梯度稀疏
权重稀疏
权重的数值分布比较像正态分布,而且越接近0,权重越多。
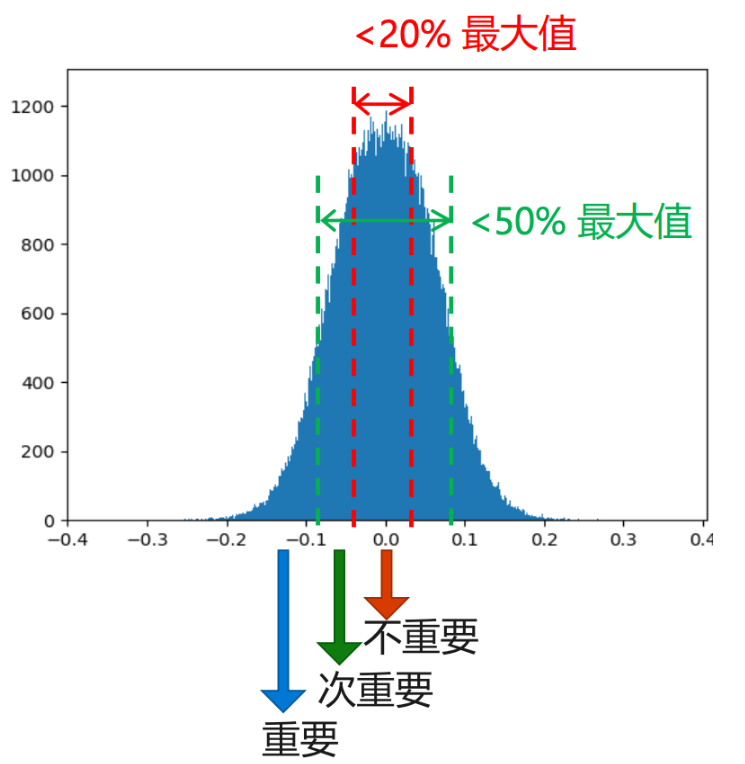
卷积层的剪枝敏感性大于全连接层,且第一层卷积层最为敏感。
剪枝三段式工作 pipeline :训练、剪枝、微调
对硬件加速不友好,尤其是GPU,因为稀疏后得到的矩阵是高度非规则的矩阵。
激活稀疏

APoZ高 –> 冗余
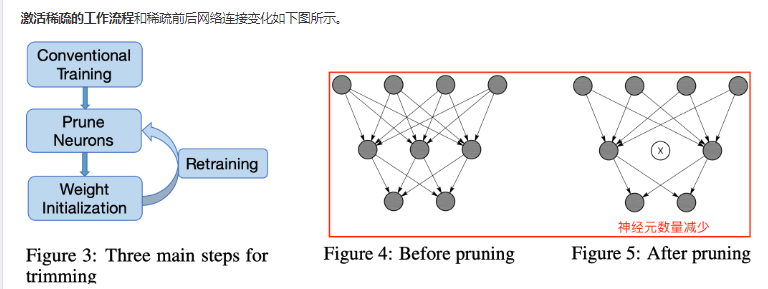
剪枝三段式工作:
- 正常训练,然后在大型数据集上运行网络以获得每个神经元的APoZ。
- 根据标准修剪高APoZ的神经元,并移除相应的神经元连接。
- 使用修建前的权重初始化之后再重新训练一遍。
结构化稀疏(粗粒系稀疏、块稀疏)
channel/filter-wise减少网络通道shape-wise
一般都是丢弃整行或整列的权重,或者卷积层中的整个滤波器。
结构化剪枝包含通道剪枝和块剪枝等技术。通道修剪侧重于消除内核内的整个通道过滤器,而块修剪则在更大范围内进行,通常针对完整块。
摘要
提出一种新颖的子网块修剪策略和渐进式训练方法,而且扩展到transformer模型,效果很好
介绍
主要贡献:
(1)我们提出了一种统一且高效的深度剪枝方法来优化 CNN 和视觉 Transformer 模型。
(2)我们提出了一种用于子网优化的渐进式训练策略,以及一种使用重新参数化技术的新颖的块修剪策略。
(3) 对 CNN 和视觉 Transformer 模型进行全面的实验,以展示我们的深度剪枝方法的优越剪枝性能。
深度卷积减少计算量和参数,但是内存占用增加
相关工作
(未完待续)