Segment Anything
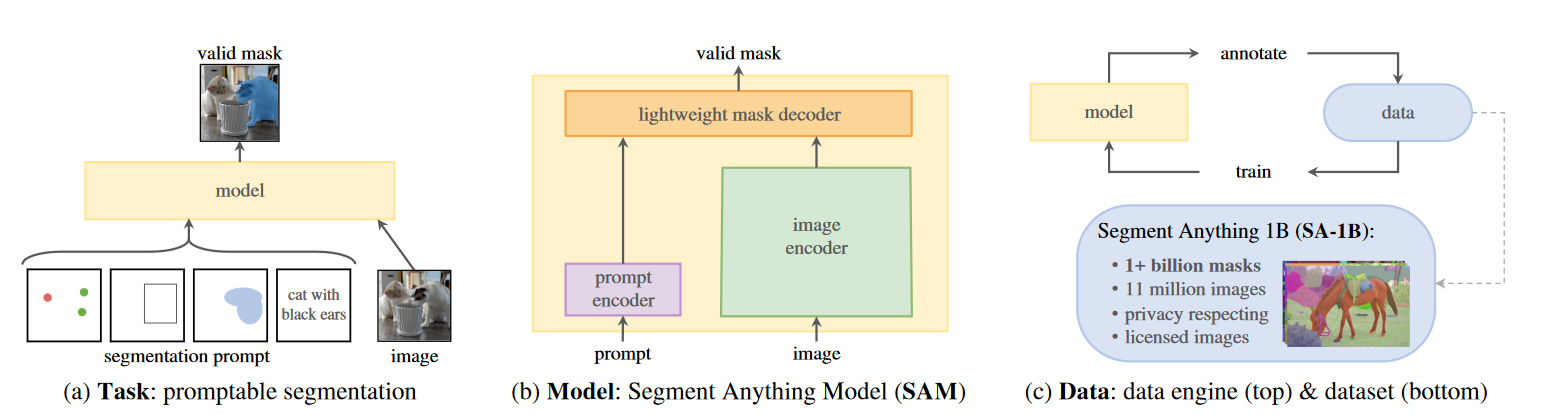
Task(提示分割任务)
作为预训练,流程就是:给一个prompt(提示)和对应的图,返回一个有效的掩码。
仔细解释一下,
prompt只是指定在图像中分割什么。
有效输出掩码意味着,即使给的提示不明确甚至可能涉及多个对象,输出也应该是一个合理的掩码的至少其中一个对象。
Model(SAM)
首先要满足三个条件:
- 必须支持灵活的提示
- 需要实时计算掩码以允许交互使用
- 必须具有模糊意识
流程如下:prompt进入提示编码器嵌入提示,image进入图像编码器计算图像嵌入,然后将两个信息源组合在一个轻量级掩码解码器中(在解码器里预测分割mask),然后输出一个有效的掩码。
在这其中,可以使用不同的prompt搭配相同的图像嵌入。
为了SAM能够更好的感知处理歧义,作者还预测单个提示的多个掩码。
细节:
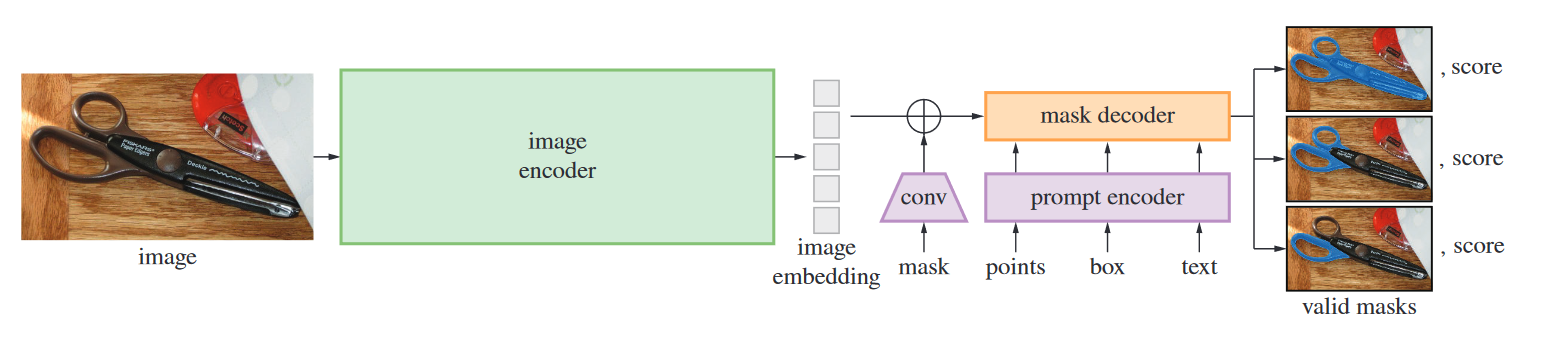
Image encoder(图像编码器):使用MAE预训练的vit,为了处理高分辨率输入。
Prompt encoder(提示编码器):使用CLIP中现成的文本编码器对每种提示类型和自由格式文本进行学习嵌入。使用卷积嵌入mask,然后与图像嵌入按元素求和(add)。
Mask decoder(掩码编码器):掩码解码器有效地将图像嵌入、提示嵌入和输出标记映射到掩码。
过程:采用了 Transformer 解码器块 的修改,后跟动态掩模预测头。修改后的解码器块使用两个方向的即时自注意力和交叉注意力(即时图像嵌入,反之亦然)来更新所有嵌入。运行两个块后,我们对图像嵌入进行上采样,并且 MLP 将输出标记映射到动态线性分类器,然后计算每个图像位置的掩模前景概率。
Resolving ambiguity(解决歧义):改成预测单个提示的多个输出掩码,发现三个掩码输出足以解决最常见的问题(整体、部分、子部分)
Losses:我们使用焦点损失和骰子损失的线性组合来监督掩模预测。
Data(Data engine数据引擎 & Dataset)
为了构建了一个数据引擎,分为三个阶段:辅助手动、半自动和全自动。
在第一阶段,SAM 协助注释者注释掩模,类似于经典的交互式分割设置。
在第二阶段,SAM 可以通过提示可能的对象位置来自动为对象子集生成掩码,而注释器则专注于注释其余对象,从而帮助增加掩码多样性。
在最后阶段,我们使用前景点的规则网格提示 SAM,每张图像平均产生 大概100 个高质量掩模。
数据集是SA-1B,包括来自 11M 许可和隐私保护图像的超过 1B 个掩码。