学习书籍:《深度实践OCR:基于深度学习的文字识别》
OCR是什么?
文字识别(OCR,Optical Character Recognition)是视觉感知中的一个重要技术,目的是从照片中提取文字信息。
发展史
模式匹配(可以识别1k个印刷体汉字)->基于K-L数字变换的匹配(可以识别2k个印刷体汉字,但是造价昂贵)->LeNet5网络使OCR达到了商用的水平->AlexNet网络使cv技术进入爆发期,识别和检测间接促进了OCR技术的发展
发展阶段
传统OCR技术方法 and 基于深度学习的OCR技术方法
有关的专用名词:
DAR(Document Analysis and Recogition,文档图像分析和识别)
STR(Scene Text Recognition,场景文字识别),是OCR的重要分支。
传统OCR方法一般流程
序列化标注问题,主要目标是寻找文本串图像到文本串内容的映射,一般分解流程如下图所示:(合乎人类视觉处理逻辑)
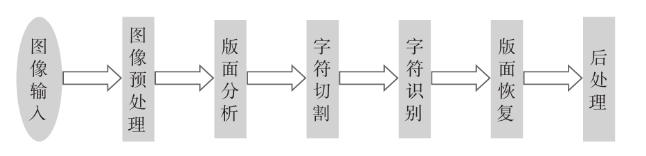
step 1 图像输入: 对于不同的图像来说,因为有着不同的格式和压缩方式,所以需要使用不同的方法进行解码;
step 2 图像预处理: 主要包括二值化、去噪声、倾斜矫正等;
step 3 版面分析: 对文档图片分段落、分行的过程,称为版面分析;(没有固定统一的切割模型)
step 4 字符切割: 因为需要对每个字做识别,所以需要将版式的文字切割成一个个单字,以便用于后续的识别分类器的使用;
step 5 字符识别: 由早期的模板匹配,到后期的特征提取;
step 6 版面恢复: 根据识别后的文字,回归到原始的文档图片那样显示,段落、位置和顺序都不变的输出到 Word 文档和 PDF 文档等;
step 7 后处理: 根据语言模型,对识别的结果进行语义校正。
涉及到的问题:
- 处理流程的工序太多,而且是串行的,这使得错误会被不断放大
- 涉及太多的人工设计,不一定能抓住问题的本质
深度学习的自适应学习驱动方式可以很好地应对这些问题:
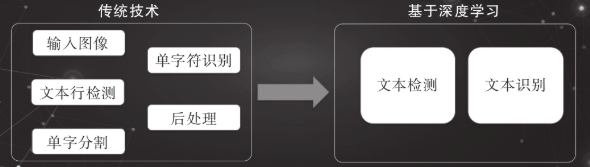
文字检测
手动提取特征
(感觉理论又臭又长,实际上会神经网络的基础基本就能看懂,等以后有空再写吧)