全称:Fully Attentional Network for Semantic Segmentation
全注意力模块代码:
1 | class FullyAttentionalBlock(nn.Module): |
abstract
在原来可以通过压缩空间维度或通过压缩通道的相似图来描述沿通道或空间维度的特征关系,但是这样会沿着其他维度压缩特征依赖性,就会导致注意力缺失,对小类别的结果较差或者大对象内分割不一致。
Introduction
在FLANet中,将空间和通道注意力编码到在单个相似图中,同时保持高计算效率。
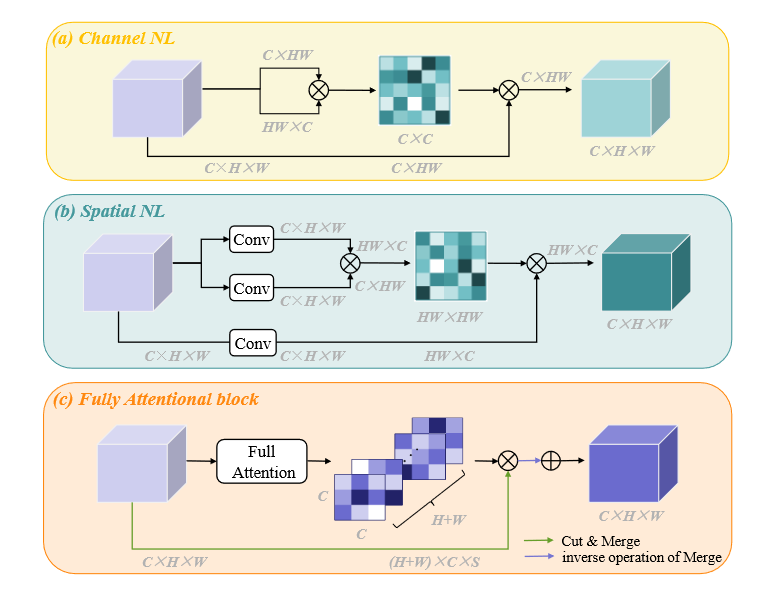
空间NL可以增强细节的辨别力,而通道NL则有利于保持大对象内部的语义一致性空间NL可以增强细节的辨别力,而通道NL则有利于保持大对象内部的语义一致性。
而且单纯把两个NL模块堆叠起来使用还是会出现注意力缺失的问题,注意力缺失问题会损害特征表示能力,并且不能通过简单地堆叠不同的NL块来解决。,但是FLA解决了这一问题。
FLA基本思想:在计算通道注意力图时利用全局上下文信息来接收空间响应,从而能够在单个注意力单元中实现充分的注意力,并且具有较高的计算效率。具体来说,我们首先使每个空间位置能够从具有相同水平和垂直坐标的全局上下文中获取特征响应。其次,我们使用自注意力机制来捕获任意两个通道图之间的完全注意力相似性以及相关的空间位置,最后,通过整合所有通道图和相关全局线索之间的特征,使用生成的完全注意相似性来重新加权每个通道图。
Method
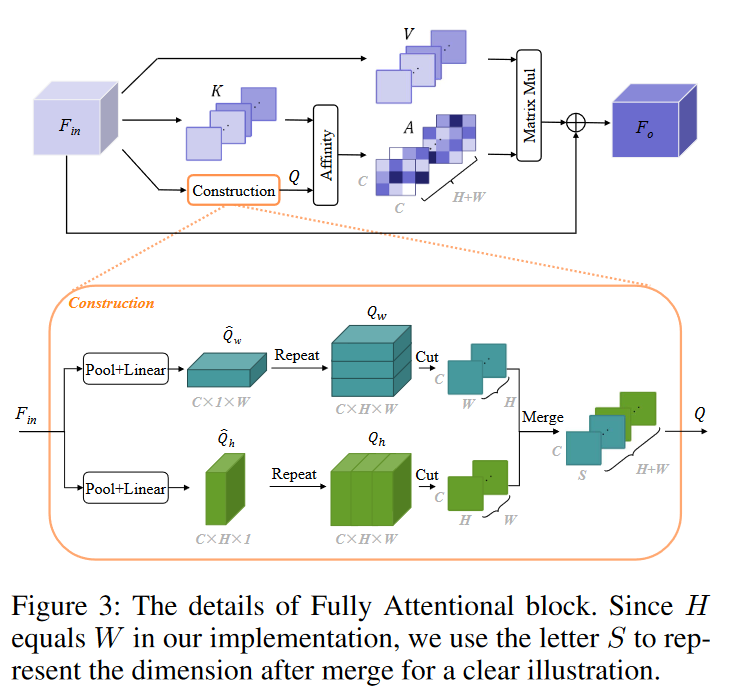
为了避免增加额外的计算负担,我们尝试利用全局平均池化结果作为全局上下文先验,将空间交互引入通道NL机制。
具体计算过程:
给定输入特征图 Fin ∈ RC×H×W ,其中 C 是通道数,H 和 W 是输入张量的空间维度。首先,我们将 Fin 输入到底部的两个平行路径(即构建),每个路径都包含一个全局平均池化层,后面跟着一个线性层。在选择池化窗口的大小时,我们考虑了以下两个方面。首先,为了获得更丰富的全局上下文先验,我们选择在高度和宽度方向上使用不相等的全局池化大小而不是内核像3×3这样的窗口。其次,为了确保每个空间位置都与具有相同水平或垂直坐标的相应全局先验连接,即在计算通道关系时保持空间一致性,我们选择保留一维的长度持续的。因此,我们在这两个路径中分别采用大小为 H × 1 和 1 × W 的池化窗口。这给出 ˆ Qw ∈ RC×1×W 和 ˆ Qh ∈ RC×H×1。之后,我们重复 ^ Qw 和 ^ Qh 形成全局特征 Qw ∈ RC×H×W 和 Qh ∈ RC×H×W 。请注意,Qw和Qh分别表示水平和垂直方向上的全局先验,它们将用于实现相应维度上的空间交互。此外,我们沿 H 维度切割 Qw,从中我们可以生成一组大小为 RC×W 的 H 切片。同样,我们沿着W维度切割Qh。然后我们合并这两个组以形成最终的全局上下文 Q ∈ R(H+W )×C×S。剪切和合并操作如图3 所示。同时,我们沿 H 维度切割输入特征 Fin,产生一组大小为 RC×W 的 H 切片。同样,我们沿着 W 维度进行此操作。与 Q 的合并过程一样,这两组被整合形成特征 K ∈ R(H+W )×S×C 。以同样的方式,我们可以生成特征图V ∈ R(H+W )×C×S。
贡献:
- 发现非局部自注意力方法中存在注意力缺失问题,这会损害特征表示的完整性。
- 我们将自注意力机制重新表述为完全注意力方式,以生成密集且全面的特征依赖关系,从而有效且高效地解决注意力缺失问题.
- 实验广泛。
不足:
极高的计算量限制了其实际应用.