看了一篇24年的综述,所以整理了一下
链接:http://cjig.cn/zh/article/doi/10.11834/jig.230659/
代码:https://github.com/xzz777/Awesome-Real-time-Semantic-Segmentation
传统图像分割
包括多种基于区域和基于边界的算法
OTSU法、K均值聚类、分水岭、区域生长法、活动轮廓、图割法、条件随机场、马尔代夫随机场等。
提出深度学习之后提出了
全卷积网络FCN
卷积神经网络CNN
–>需要恢复下采样损失的信息
–>多尺度的特征信息、长距离的上下文(提升精度显著)
–>丰富上下文信息的方法:扩大感受野、多尺度融合、自注意力机制
- 更好的特征提取网络
VGG(2015)
GoogLeNet(2015)
ResNet(2016)
HRNet(2019)
- 更好的上下文捕获方法
U-Net(2015)
PSPNet(2017)
RefineNet(2017)
- 添加注意力模块的CNN
Transformer被提出之后引入cv领域
SETR(2021) 首次将视觉transformer应用到图像分割
PVT(2021) 将常用的特征金字塔架构引入基于transformer图像分割的模型
SegFormer(2021) 提出一个简洁、高效且多尺度的TransFormer图像分割模型
Swin Transformer(2021) 可代替CNN
–>精度显著提升,但是带来了高额的计算代价;尤其是自注意力机制和自注意力机制为核心的transformer网络,虽然有全局建模能力,被证实非常适合捕获长距离上下文,但是与图像分辨率呈平方复杂度,显著增大了语义分割模型的推理延迟
一般而言,实时语义分割网络是指在指定设备上,推理时的帧率能够达到30帧/s及以上(即人眼对视频流畅的最低帧率要求)的语义分割网络。
挑战:
为了得到更高的分割精度,语义分割模型同时需要丰富的空间细节信息和多尺度上下文信息。然而,一方面,丰富的空间细节信息需要保留高分辨率的底层特征图,这会极大地增加计算代价;另一方面,多尺度上下文的捕获和融合又需要设计复杂的模块和交互,这会增加推理的延迟。如何以更少的计算代价,保留更丰富的空间信息、捕获更有效的多尺度上下文,以得到更好的模型速度—精度平衡,是实时分割领域一直以来的挑战和领域内研究者们一直以来的追求。此外,在一些资源受限的移动设备和边缘设备上,模型的大小和内存占用量也显得至关重要,在这些设备上的实时语义分割网络如何进行优化设计也是实时分割领域面临的一项挑战。
- 单分支网络
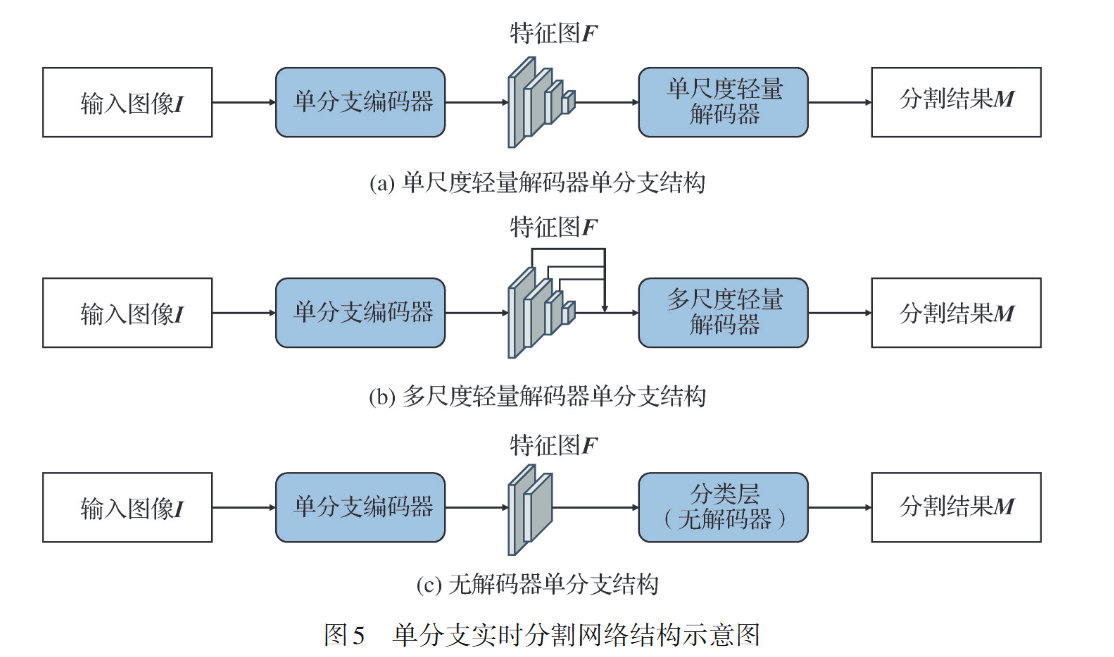
(1)解码器利用编码器最后的输出进行特征回复和解码(代表:ENet)
(2)利用多尺度特征进行简单拼接融合(代表:SegFormer和SegNext)
(3)舍弃解码器,直接对编码器特征进行分类输出
ENet:在前两个模块进行下采样,使用更小的特征图进行后续操作。
认为解码器的作用是对编码器的输出进行上采样,只对细节进行微调,编码器本身应具有信息处理和过滤的作用。
优点:推理速度显著提升
缺点:精度较低
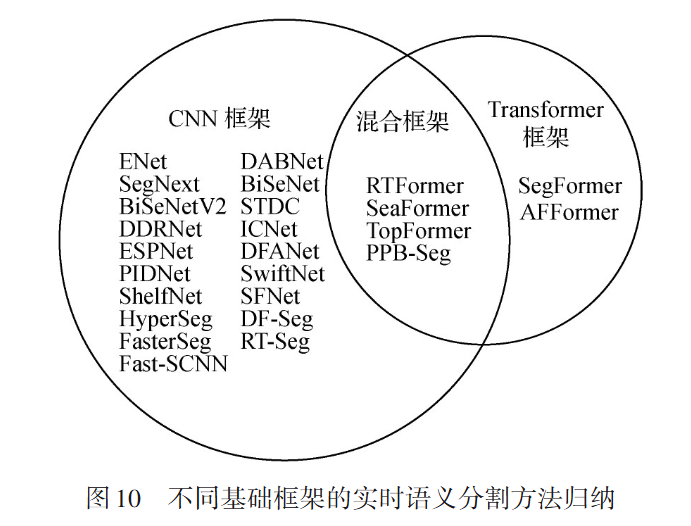
实时语义分割研究方案主要分为三类:
1)设计轻量化模块结构,如DUpsampling模块、ERF-PSPNet采用的残差分解卷积模块等;
2)设计新型网络设计范式,如ICNet 和 BiSeNet采用的多支路进行信息补充的结构、将超分辨率算法引入指导低分辨率图像语义分割的方式、利用知识蒸馏指导实时语义分割网络的训练等;
3)采用轻量级基础网络提取低级特征信息,如SwiftNet和DFANet等。